图像超分辨率
图像超分辨率
该项目为南加州大学 EE 541 的大作业,由张靖祥和钟路迦共同完成。
点击此处查看更多详细信息。
摘要
目的: 这是一个图像超分辨率 (SR) 项目。我们使用 DIV2K 数据集从低分辨率图像中恢复高分辨率图像。图像超分辨率是图像传输的关键步骤,它在卫星图像遥感、数字高清等其他领域也有许多重要的应用。该问题有很多传统计算机视觉解决方案,包括基于插值的方法、基于重建的方法和基于学习的方法。
我们首先测试了各种图像超分辨率模型,以提高常见图像的质量,使用峰值信噪比 (PSNR) 和结构指数相似性 (SSIM) 作为模型性能的标准,并比较深度学习模型和使用 Bicubic 与其他插值的传统算法。最后,我们将在整个训练集上测试我们最好的模型并分析结果。
在扩展工作中,我们将 1) 比较patch(子图像)大小和 batch size 如何影响训练过程,2)我们设计了一个实验来证明只训练 Y 通道是合理的,并且比同时训练 RGB 通道更好,3)我们将比较缩放倍数如何影响预上采样模型。
模型: SRCNN, FSRCNN, ESPCN, VDSR, SRGAN, EDSR, DCSCN, SUBCNN, Per. SRGAN
点击此处查看完整报告。
扩展项目:
在这个项目中,我主要做了介绍部分和扩展部分的内容。因此,我将简要介绍一下我的实验结果。在这里,我将提出3个关于超分辨率的问题:
- patch 大小(子图像)如何影响训练?
- channel 如何影响训练?
- scale factor如何影响 pre-upscaling 的模型?
1. Patches 大小
在大多数超分辨率网络模型中,默认的图像预处理方法是将训练图像切割成小块,并通过这些小块来训练网络。Dong et al. 建议使用 33*33 作为子图像大小,步长等于 14。同样,Zhou, et al. 在论文中说明 step 越小,MSE 越小,并且他们使用的补丁大小范围从 3*3 到 13*13。在我们之前的实验中,我们使用了等于 50 的 patch 大小。这些默认设置引起了我们的好奇,子图像 pathc 大小会影响训练过程吗?因此,我们设计这些实验来比较给定不同补丁大小的训练过程。
我们将使用 ESPCN 模型,因为它是一个相对简单的模型,使用 MSE 损失作为损失函数。通过 Adam 优化器训练模型,从 0.01 开始每个 epoch 的学习率衰减 0.9。训练的 batch 大小为 16。我们将训练图像切割成 32*32、64*64、128*128 和 256*256,并且没有重叠,并在图像边界中用 0 填充(而不是丢弃它)。此外,我们将 RGB 通道转换为 YCbCr 通道,并且只训练和比较 Y 通道上的性能与之前的设置。在这里,我将训练模型 20 个 epoch。20个epoch可能还没有完全收敛,可能还没有达到最好的性能,但我们的目标只是对训练过程进行比较。
下图显示,当 patch size 等于 64 时,模型将获得最佳性能。等于 32 的 patch 大小也是一个不错的选择,但是 patch 大小越小,训练时间就越长。当 patch 大小大于 64 时,patch 大小越大,性能越差。
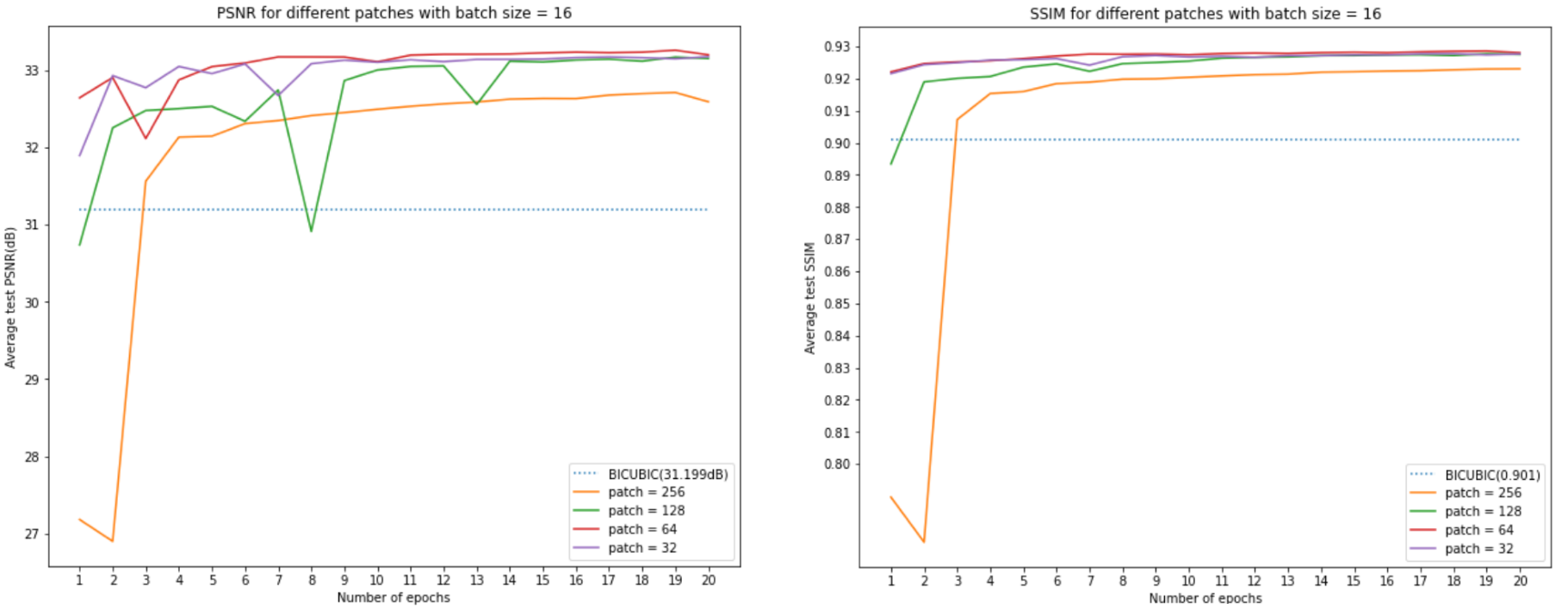
然而,应该注意到,对于较小的 patch 大小,每个时期都有更多的迭代次数,即每次迭代时输入到模型中的数据是不同的。较小的 patch 的优点是它可以为每个 epoch 训练更多的迭代。为了确保输入到模型中的数据大小具有相同的大小,我们设计了另一组训练。对于等于 32、64、128 和 256 的 patch 大小,我们使用批量大小等于 1024、256、64、16。这次,输入数据具有相同的大小,并且每个 epoch 的迭代彼此接近(因为我们在裁剪的时候填充了图片,子图越大,padding的空白也越大,所以这里的迭代次数不会相等)。
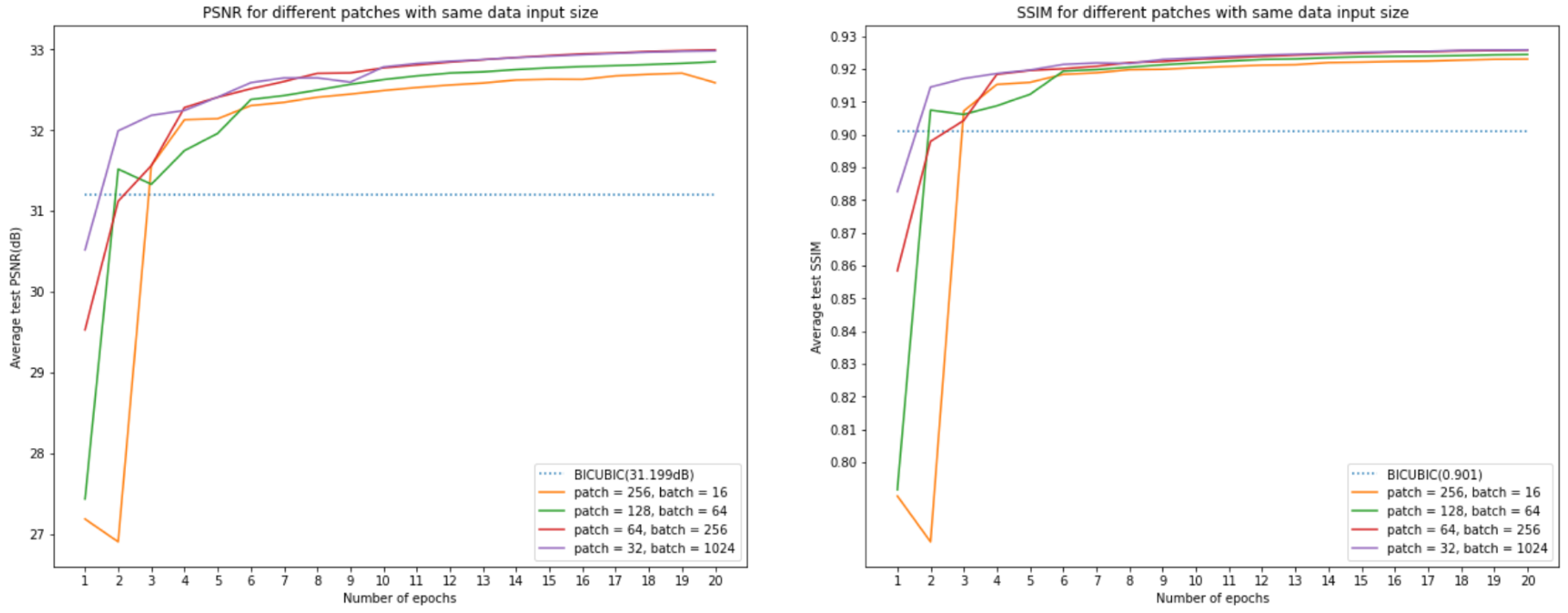
上图显示,即使我们保持相同的输入数据大小,patch 大小等于 32 或 64 仍然可以获得最佳性能,而且 patch 大小越大,性能越差。下表显示了验证集上的最终测试性能。
这部分的结论是:表 3 显示,当批大小等于 16,补丁大小等于 64 时,模型将获得最佳性能。然而,应该注意到它会花费更多的时间来训练更多的迭代。所有这些 patch 大小和 batch 大小设置之间的训练时间可能因模型而异。
2. 训练 Channel
在几乎所有的超分辨率研究中,原始图像都会转换成YCbCr通道,并且只使用Y通道来训练模型。 YCbCr颜色空间中,Y指亮度分量,Cb指蓝色色度分量,Cr指红色色度分量。由于人类视觉对亮度变化比对色彩变化更敏感。在这一部分中,我们将尝试验证仅训练 Y 通道是否合理。
这部分我们还是会使用 ESPCN 模型,使用 MSE 作为损失函数,通过 Adam 优化器训练模型。从 0.01 开始每个 epoch 的学习率衰减 0.9。训练的batch size为64,patch(子图像)大小为64*64。我们将训练模型 20 个 epoch,并记录每个 epoch 的 PSNR,不使用 SSIM。
对于第一个模型,我们只训练 Y 通道。首先,我们读取低分辨率图像作为LR并将图像转换为YCbCr,提取 Y 通道作为 LR。然后我们对 LR 进行 Bicubic 插值得到LR After,将 LR After 转换为 YCbCr,提取 Cb 和 Cr 通道作为LR。在 Cb 和 LR 之后,在 Cr 之后。我们将LR Y作为ESPCN模型输入,得到LR After Y。最后将LR After Y、LR After Cb、LR After Cr拼接在一起,转换回LR After RGB。然后我们读取高分辨率图像为 HR RGB 并将图像转换为YCbCr,提取 Y 通道为 HR Y。我们将计算 LR Y 和 HR Y 的 PSNR 作为第一对,LR After RGB和HR RGB为第二对。在我们的预期中,第一对的 PSNR 将高于第二对,因为该模型是在 Y 通道上训练的。但是 LR After RGB 和 HR RGB 的 PSNR 不会太低,因为 Y 通道是主要通道。
对于第二个模型,我们将RGB通道一起训练,模型的输入通道为3,输出也为3。PSNR由RGB通道一起计算。
对于第三个模型,我们将分别训练R、G、B通道,每个模型只训练一个通道,并在自己的通道上计算PSNR。最后,我们将平均 PSNR 作为模型性能。
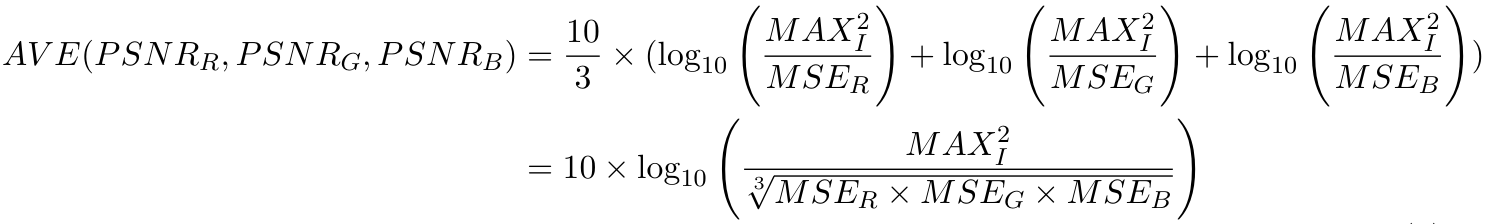
但是,真正的 RGB 通道 PSNR 应该在下一个公式中计算。但在这种情况下,MSER + MSEG + MSEB 的算术平均值和几何平均值非常接近。我们使用前面的公式作为 PSNR 性能。
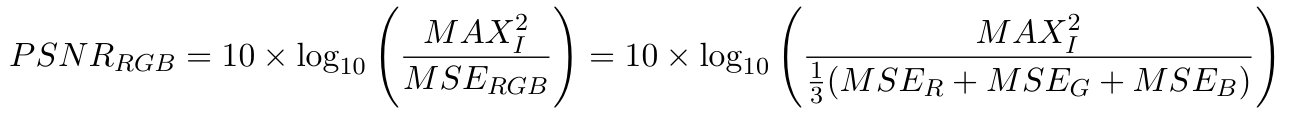
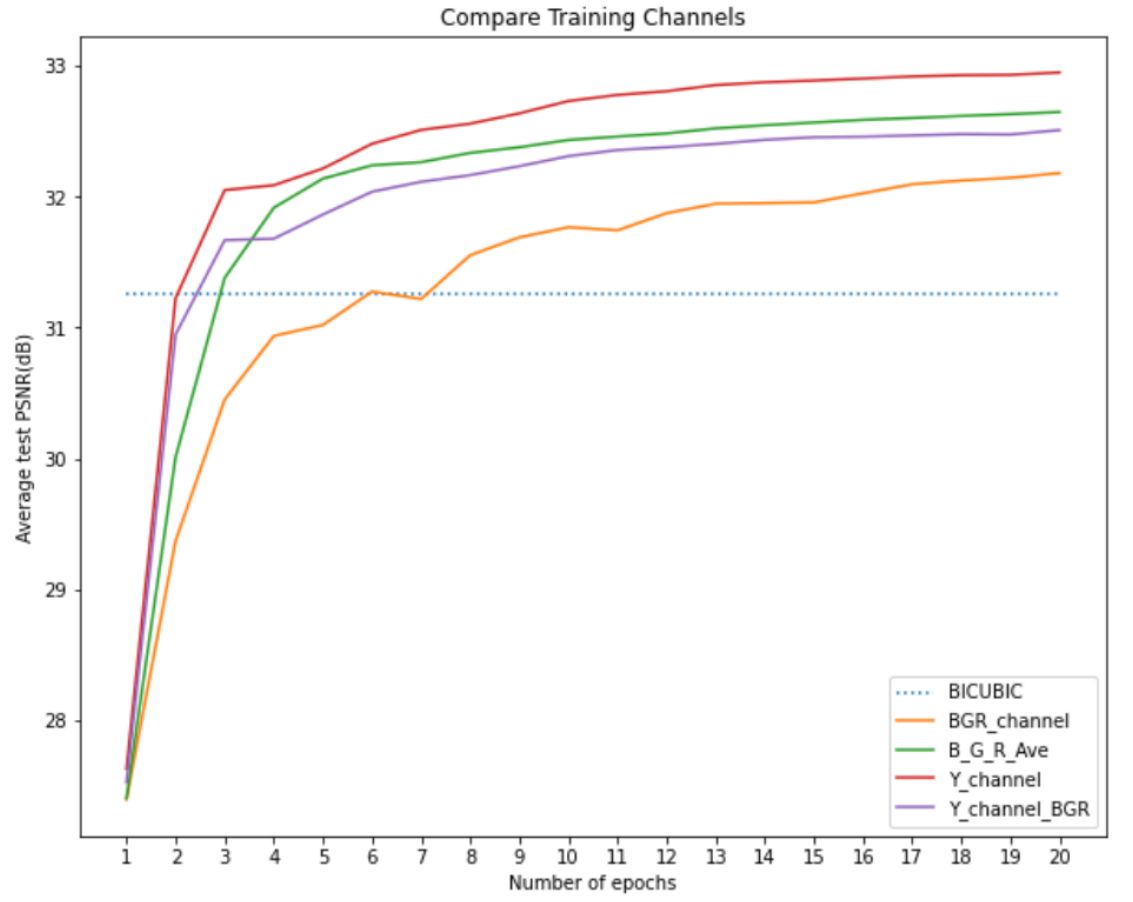
上图显示了 ESPCN 模型使用不同训练通道的训练曲线。 Y channel 表示模型在 Y 通道上训练,PSNR 用于 Y 通道比较,而 Y channel BGR 表示模型在 Y 通道上训练,PSNR 用于 RGB 通道比较(这里我们使用 BGR因为 OpenCV 通过 BGR 通道读取图像)。 BGR channel 代表在 RGB 通道上一起训练的模型,B G R Ave 代表分别在 R、G、B 通道上训练的 3 个模型的平均 PSNR。
从这个图中,我们可以发现最差的模型是一起在BGR通道上训练的。虽然分别在 B、G 和 R 上训练仅比仅在 Y 通道上训练略好(与 BGR 通道上的 PSNR 相比)。如果有足够多的 epoch,它们最终可能会达到相同的性能。但是,训练三个模型会花费更多时间。因此,只训练Y通道是很合理的。

上图显示了测试图像上的性能,所有模型都比传统的 Bicubic 模型好。根据该图,很难说出这三个模型之间的区别。但是,可以发现下面的所有三张图片都在黑线周围出现了波纹。由于ESPCN使用了卷积层,和很多filter一样,黑线中的黑色会影响周围的区域,所以黑线周围会出现波纹。
3. 上采样倍率
在Pre-upsampling SR算法中,算法会先通过Bicubic插值对图像进行上采样,然后将图像输入到模型中。我们的训练图像是低分辨率图像,标签是高分辨率图像。模型本身就是在低分辨率图像和高分辨率图像之间找到一个映射。所以,我们想知道,如果输入的训练图像是分辨率非常低的图像,那么模型必须更有能力将低分辨率图像恢复为高分辨率图像。
因此,我们设计这部分来验证我们的想法。对于所有训练图像,我们将图像下采样 n 倍,然后将图像上采样 n 倍,新图像将用作低分辨率训练图像。此数据集标记为 Data Xn。在这部分中,我们将使用 2、3、4 和 5 作为比例因子,然后我们有数据 X2、数据 X3、数据 X4 和数据 X5 数据集。使用SRCNN作为模型,训练超参数与之前的设置相同。因此,我们将通过这4个数据集训练4个模型,并将它们命名为SRCNN X2、SRCNN X3、SRCNN X4、SRCNN X5。
Dong et al. 一对一比较的PSNR和SSIM,即用SRCNN X2测试性能数据X2,用SRCNN X3测试性能数据X3,以此类推。在我们的预期中,SRCNN X5 具有最好的图像恢复能力,那么即使在数据 X2 中它也应该优于 SRCNN X2。因此,我们将使用每个模型来测试每个数据集,这将是 4 × 4 = 16 PSNR 和 SSIM 结果,并找出哪个模型最适合每个数据集。
这部分的另一个应用是假设我们有一个SRCNN X2预上采样模型,我们想把一张图片放大3倍,我们可以使用这个模型吗?还是我们需要训练一个新的 SRCNN X3 模型?如果 SRCNN X2 模型在数据 X3 上的表现与 SRCNN X3 大致相等,那么我们就不需要训练新模型了。
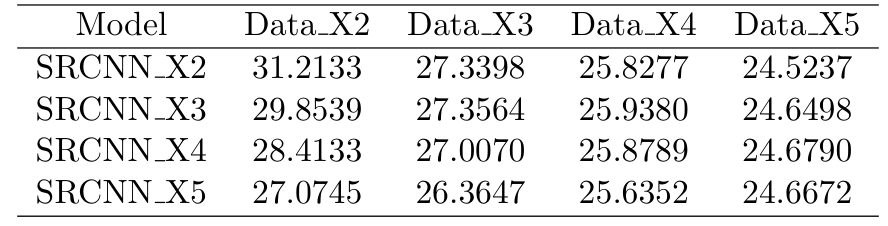
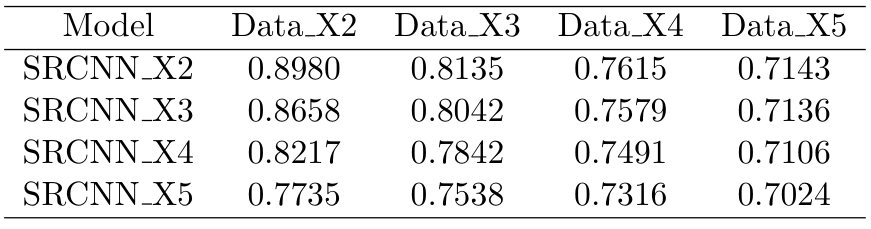
上两图显示了不同规模数据集和模型的 PSNR 和 SSIM。比较SRCNN X2和SRCNN X3模型,我们可以发现SRCNN X2在数据X2上优于SRCNN X3,SRCNN X3在数据X3上略优于SRCNN X2,这意味着我们不需要为X3图像训练新模型如果我们有 SRCNN X2。并且 SRCNN X3 在数据 X4 和数据 X5 中也优于 SRCNN X2,这符合我们的预期,因为 SRCNN X3 更适合将更模糊的图像映射到高分辨率图像。
通常情况下,给定数据集最合适的模型是其对应的模型。然而,SRCNN X4 和 SRCNN X5 表现更差。 SRCNN 中的卷积核大小为 9、1、5,而该模型中的感受野为 13。也许 13*13 的感受野不足以为非常低分辨率的图像输入推断出高分辨率图像,也许需要更深层次的网络来处理这个问题。
总结
在这个 SR 项目中,我们首先比较了不同模型的 PSNR、SSIM 和 Inference 速度,结果表明 VDSR、SRGAN 和 SUBCNN 对于给定的数据集和超参数具有最好的 PSNR 和 SSIM 性能。 ESPCN 具有最好的推理速度,PSNR 和 SSIM 性能仅次于最好的 3 个模型。然后我们比较了 patch size 和 batch 如何影响训练过程,它表明相对较小的 patch size 更适合训练 SR 模型。然后我们设计了一个实验来证明只训练 Y 通道是合理的,并且通常比一起训练 RGB 通道更好。最后,我们发现放大因子会影响预上采样模型,给定放大因子的最佳模型是其对应的放大模型。