森林火灾预测
森林火灾预测
这是南加州大学 EE 559 的期末项目。点击此处阅读报告全文。在这里,我只对这个项目做一个简单的介绍和总结。
点击此处 查看详细信息。
摘要
Algeria夏季火灾频发,利用传感器数据建立火灾预测模型至关重要。为了找到最佳模型,我将使用 3 个月的数据作为训练数据集,1 个月的数据作为测试数据集。使用交叉验证方法分离训练数据集。
在训练之前,我会展示数据,并使用Nearest Mean Classifier来比较4种数据预处理方法,包括PCA,标准化,删除夜间数据,通过最近N天的平均值/最小值/最大值增加新特征。并发现单独使用标准化将获得最佳性能。
在模型选择和训练部分,我会尝试使用4个模型,分别是Nearest Mean Classifier、KNN、SVM和bayes。比较这些模型的 F1 分数、准确率、精确率、召回率和混淆矩阵,最终通过线性核 SVM 获得最佳性能。
本项目将用到Python及其对应的库Numpy、sklearn、pandas、json、scipy。
关键字: 分类, KNN, SVM, bayes, python.
数据集介绍
这个数据集有10个特征,列举如下: 1)温度 2)RH:湿度 3)Ws:风速 4)Rain:雨量级 5)FFMC:Fine Fuel Moisture Code(相对易燃性指标) 6)DMC:Duff Moisture Code(同6) 7)DC:Drought Code(同6) 8)ISI:Initial Spread Index(火势蔓延的能力) 9)BUI:Buildup Index(可供燃烧的燃料量)
我会使用四种数据预处理的方法,分别是标准化、PCA、添加新特征、数据按昼夜分离。在PCA中,我会保留能加起来贡献率在90%以上的维度。而在添加新特征的方法中,我会在原有特征的基础上创建新的特征,比如温度或湿度。使用最近 N 天的平均值/最小值/最大值分隔白天和夜晚。通过使用这种方法,我将尝试删除原始特征并用新特征替换它,或者保留原始特征。当使用最近 N 天的信息时,我会在训练数据集中删除最近 N 天的信息,因为这些信息将用于测试数据集中。
技术路线图
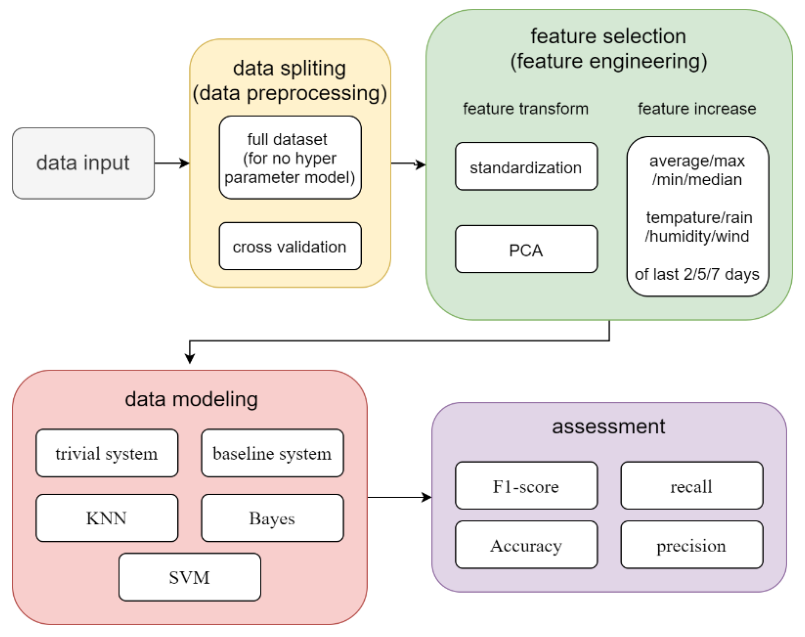
复杂度分析
由于不同的数据预处理策略,训练模型的完全可能组合将呈指数增长。是否标准化是两种可能的选择。是否使用交叉验证是两种可能的选择。是否丢弃夜间数据是两种选择。用不用PCA,用什么贡献率,都会有A种可能的选择。添加什么类型的特征,多少类型的特征,会有B种可能的选择,使用MAX/MIN/AVE会有3种选择,最后使用了N天,N是另一个变量。因此,不管学习过程中的超参数是多少,都会有2*2*A*B*3*N种可能的选择,那是海量的选择。为了尽量减少工作量,我会假设在每个学习模型中,这些变量都是凸函数的。也就是说,如果我使用 SVM 模型,并且使用交叉验证的准确性比不使用更好,那么我会假设无论我使用什么策略,我都会在拆分数据时保持交叉验证
模型选择
1. Nearest Mean 分类
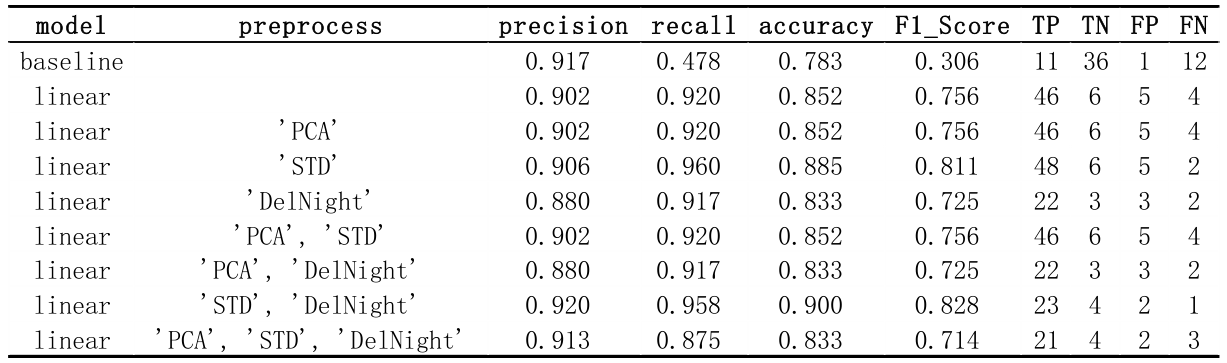
请注意,在基线系统中,TP 和 TN 与其他结果相比是完全颠倒的。根据交叉检查,这不是错误,因为基线系统使用了测试集,而其他所有结果都使用了验证集。
但还有另一个棘手的问题。因为8月份火多,所以8月份的数据会偏的不堪入目。 F1_Score 将超越所有其他数据。因此,从现在开始,我将放弃 8 月的数据作为验证集。
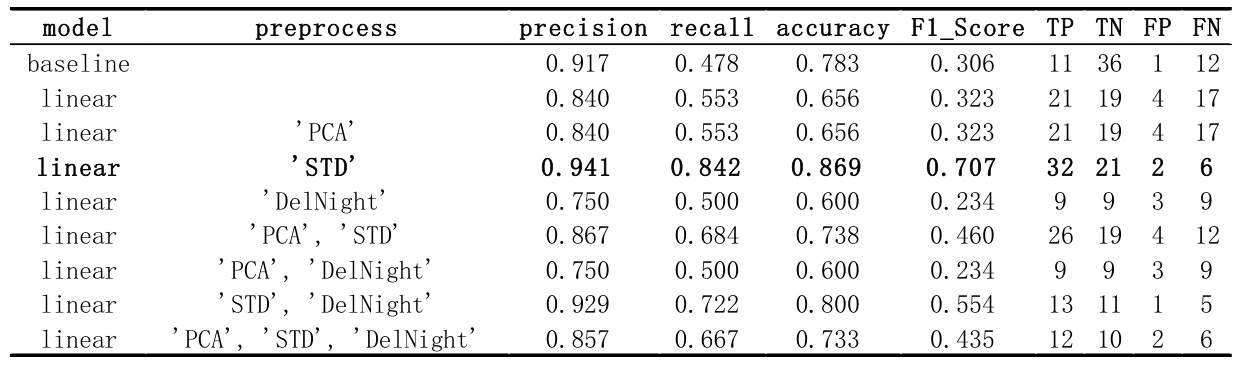
结果表明,只有将标准化作为预处理方法才能获得最佳性能。从今以后,所有数据输入都将在之后的所有模型中标准化。
标准化后添加数据的一项新功能。原始特征有9个,每个新特征我都会尝试maximal/minimal/average 3种方法,在每种方法中,我会用到最后2/3/4天。总共会有 933=81 种可能的组合。下面的部分结果表明,这个修改非常小,几乎不能改变任何东西。我想是因为之前有9个feature,稍微修改一个feature对结果影响不大。
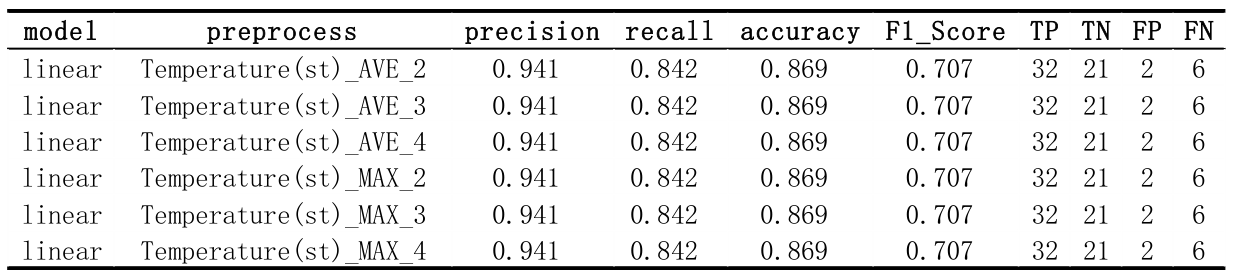
2. KNN (K-Nearest Neighbor)
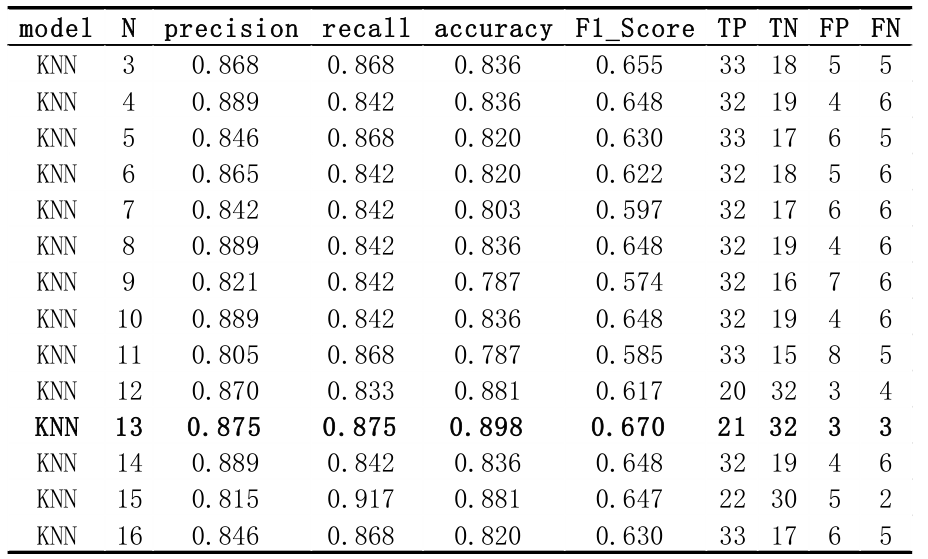
从结果来看,n = 13 有最佳性能。
3. SVM (support vector machine)
内核有4种类型:Linear, RBF, Polynomial and Sigmoid,还有3种超参数,分别对应不同的内核:
a) gamma:用于’poly’、’RBF’和’sigmoid’,大的gamma意味着更多的支持向量和过拟合;
b) degree:只用在’poly’中,通常小于或等于3。
c) coef0:用于’poly’和’sigmoid’,较低的coef0会导致欠拟合,反之亦然。
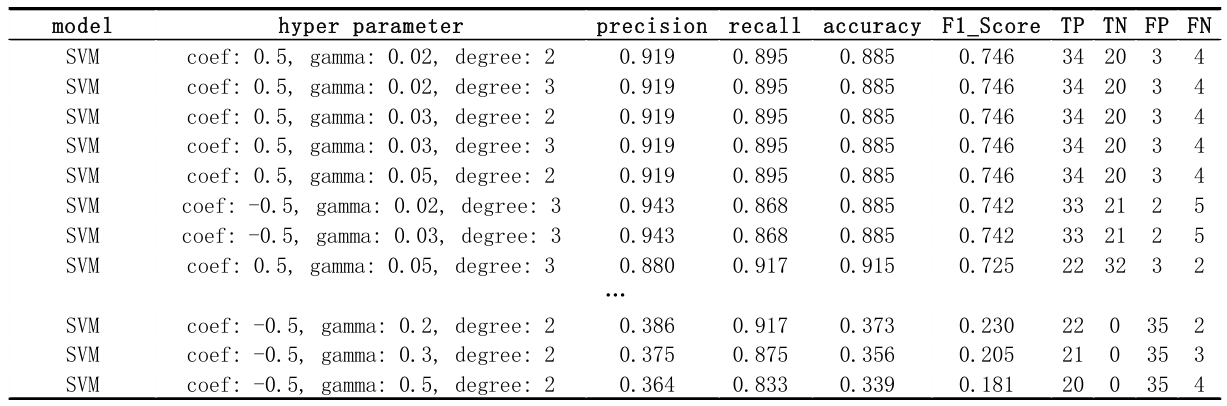
3.1 Polynomial 内核
在 polynomial 内核中,为了获得最佳性能,coefficient=0.5,gamma=0.03,degree=3
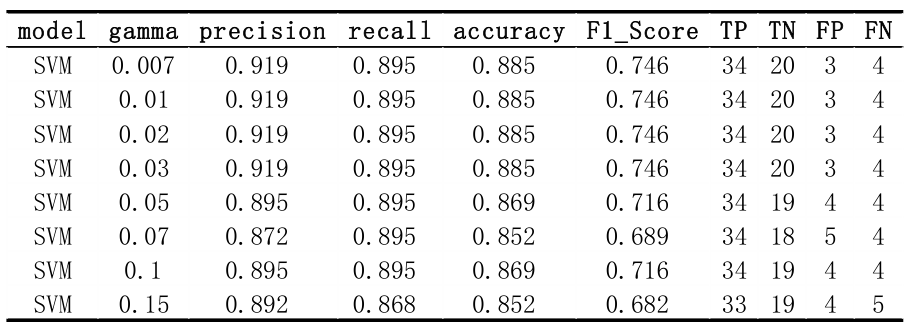
3.2 RBF 内核
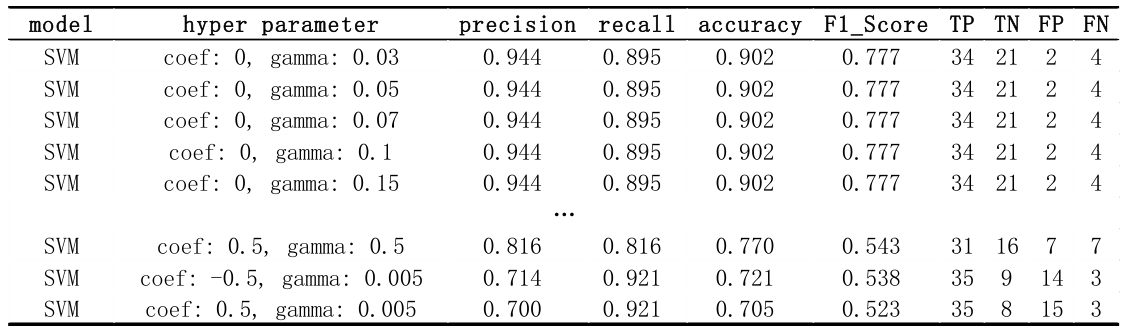
3.3 Sigmoid 内核
4. 贝叶斯
我假设数据中的每个特征都满足无相关性的高斯分布。因此,可以使用高斯分布来估计每个特征的概率密度。我将使用高斯朴素贝叶斯来进行分类。

总结
在我在问题中使用的所有数据预处理方法、所有模型和所有超参数中,最好的选择是对没有额外特征的数据进行标准化,并使用soft margin linear 内核 SVM 对数据进行分类。这是在测试集上运行线性模型、基线模型和 linear 核 SVM 模型的结果。

这三个模型没有任何超参数,因此使用交叉验证来调整模型是没有意义的。