基于光线追踪的模型渲染
基于光线追踪的模型渲染
该项目是我计算机图形学的第三次作业。在本项目中,我会用后向光线追踪的算法来渲染模型,输入是一组几何形状,输出是渲染后的图片。该项目一共有两种模式:
- 点光源渲染:

一共有三种几何形状:
- sphere
- position (3 floats)
- radius (1 float)
- diffuse color (3 floats)
- specular color (3 floats)
- shininess (1 float)
- triangle
- repeated three times (once for every vertex)
- position (3 floats)
- normal (3 floats)
- diffuse color (3 floats)
- specular color (3 floats)
- shininess (1 float)
- repeated three times (once for every vertex)
- light
- position (3 floats)
- color (3 floats)
- 面光源渲染:

一共有三种几何形状,但是与点光源相比,几何体的属性略有不同:
- sphere
- position (3 floats)
- radius (1 float)
- diffuse color (3 floats)
- roughness (1 floats)
- metal (1 float)
- triangle
- repeated three times (once for every vertex)
- position (3 floats)
- normal (3 floats)
- diffuse color (3 floats)
- roughness (1 floats)
- metal (1 float)
- repeated three times (once for every vertex)
- light
- repeated four times (once for every vertex of the area light)
- vertex position (3 floats)
- centroid position (3 floats)
- normal (3 floats)
- color (3 floats)
- repeated four times (once for every vertex of the area light)
项目配置环境
Windows系统
visual studio 2017或更高版本
第三方库:
- GLUT: 用于窗口创建
- GLEW:用于OpenGL核心库
- GLM:OpenGL数学运算库
- jpeg:图像输入输出
项目特色:
- 通过后向光线追踪渲染模型
- 使用 Phone 模型决定像素颜色
- 递归式反射
- 超级采样抗锯齿(SSAA)
- 通过蒙特卡洛采样法与BRDF的计算,实现软阴影
- 构建 bounding volume hierarchy(BVH)与混合空间分割(包括surface area heuristic(SAH))。使用线性树结构加速搜索过程。
- 在构建BVH和做光线追踪的时候使用多线程来充分利用CPU资源。
如何使用?
- 点击 RayTracingRender.sln 打开项目
- demonstration 文件夹展示了渲染结果
- release 文件夹包含了项目编译后的版本,你需要提供2到3个额外的参数
- 待渲染的模型路径
- 输出图像的路径
- 渲染模式(可选):
- phong:使用点光源与Phong模型进行渲染
- brdf:使用面光源与BRDF进行渲染
Bin文件夹包含了visual studio的输出。请注意项目运行需要用到 glew32.dll 与 freeglut.dll,所以你需要确保这两个文件在项目输出的目录中
main.cpp文件包含了更多的参数设定方式
点击此次获取项目源代码。
技术细节:
1. 多线程执行函数
由于创建和销毁线程都具有开销,所以,在不需要同步的场景中(http服务器)一样,使用线程池是最好的选择。 但是在 OpenGL 中,我们需要保持渲染的同步。 所以还是创建线程后再用join函数同步是更好的选择,而此时,创建和销毁线程的开销是不可避免的。
我的多线程函数实现很简单,函数在parallel.cpp文件中:
void parallelRun(const std::function<void(long long unsigned int)>& func,
const long long unsigned int length, const int nThreads = std::thread::hardware_concurrency() - 1) {
std::vector<std::thread> threads_list;
for (int thread = 0; thread < nThreads; thread++) {
std::function<void(int)> warper = [&](int start) {
for (long long unsigned int i = start; i < size; i += nThreads)
func(i);
};
threads_list.push_back(std::thread(warpper, thread));
}
for (int thread = 0; thread < nThreads; thread++) {
threads_list[thread].join();
}
}
函数的输入是一个需要并行执行的函数,length是总任务数。首先创建一个 warper 函数并分配任务,然后运行 warper 函数,最后使用 join 进行同步。
这个函数也很容易使用,下面的例子展示了如何并行输出0到99:
parallelRun([&](int i) {
std::cout << i << std::endl;
}, 100);
由于光线追踪是一个很容易并行运算的问题,我们可以使用并行运行函数来独立渲染像素。有关我如何使用此函数绘图的更多信息,请查看 plot.cpp 文件中的 draw_scene() 函数。
2. 递归式反射与衰减系数
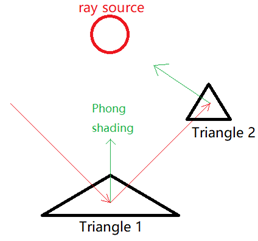
在 Phong 渲染的部分(光源是一个 0 维度的点),如果没有反射,那么渲染的结果为:

下图中,如果没有反射,那么我们只需要计算三角形 1 的 Phong shading,假设颜色为[0, 255, 0],即绿色。 但是在考虑反射的时候,我们发现反射光线是和三角形 2 相交。那么,我们要计算三角形 2 的Phong shading,而这里的颜色是[255, 0, 0],就是红色。 现在,我假设三角形2是一个光源,可以向三角形 1 发射红颜色的光。 因此,三角形 1 接收到的最终颜色将是两种颜色的重叠:[0, 255, 0] + [255, 0, 0] = [255, 255, 0]。
当使用这种策略渲染图像时,我得到了下图。 这里面的问题是,我们假设所有的物体都能完美的反射,就想镜子一样:

因此,我使用衰减系数(attenuation_reflection)作为超参数来降低反射率。 假设衰减系数等于 0.2,那么前面示例的最终颜色将为 [0, 255, 0] + [255, 0, 0] * 0.2 = [51, 255, 0]。 渲染结果为:

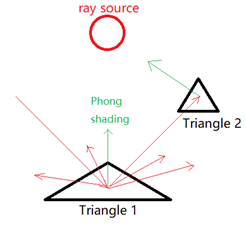
另外,规则表面不仅可以有反射,还可以有漫散射。 当光线与三角形 1 相交时,我会随机选择 n 个随机方向发射光线,对于与其他的三角形相交的每条光线,我都会假设该三角形是一个光源,并使用 Phong shading 来计算三角形 1 接收到的颜色。 而且,它需要一个衰减系数来降低漫散射率。
结果看起来与原始结果几乎相同。但仔细观察,你会发现蓝色字母下方的阴影有点偏蓝。

还有就是,由于反射主要影响渲染结果,所以只有反射光线可以递归,漫散射光线不会参与递归。 这是正则表达式中的 LDS*E, 其中 L、D、S、E 分别代表接收位置的颜色、漫反射率,镜面反射率,和光源。 最终的光线路径可以是 LDE、LDSE、LDSSE、LDSSSE,… 。
最后我把最大反射次数设为2,两个衰减系数设为0.2,结果是:

3. 超采样抗锯齿
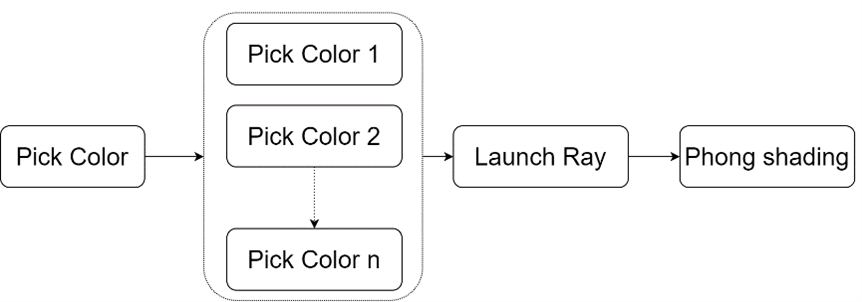
与其他部分相比,这部分很容易实现。它只需要为超级采样添加一个额外的层。 此前的流程是:

现在,当使用超采样之后,流程变为了:
这是不同尺度的超采样的对比:

通过增加超采样的点,图像的边缘变得越来越平滑:
4. 随机性的问题与解决办法:
开始的时候,我使用 rand()%1000 取随机函数,但发现它根本不是“随机”的。 因为我使用多线程做BRDF着色,所以每个线程都需要调用random函数。 当我将随机光采样数设置为 100 时,我得到了:

图像中有很多“条纹”。 因为我的笔记本CPU有16个线程,所以每次都会并行计算16个列,看起来16个线程每次pick的时候都得到了相关的随机值。 比如线程1得到的随机序列是0.1, , 0.2, 0.3, 0.4, …, 线程2得到的随机序列可能是0.2, 0.3, 0.4, 0.5, …。
我尝试通过在每个线程中添加 srand(time(NULL)) 来修复这个问题,我得到了:

结果看起来还是很奇怪,我想不通为什么会这样,只能认为这个随机数不是“随机“”的,而是有关系的。
最后,我使用 std::mt19937_64 rng; 的方法,我得到了

虽然噪音是不可避免的,但结果看起来更随机。 然后,我使用 x16 超采样,即在每个像素中,它会采样16次,并且每次会采样100个随机光源:

还是有一些杂音, 看来软影的确很难实现。
最后,包含反射:

5. 用SAH和多线程构造BVH,及其优化
该内容引用了这个链接.
直观上来讲,构建任何 BVH 都不是一个可以并行的问题。 但是我们可以通过其他一些算法来构建 BVH。 所以,这里是算法的关键思想:
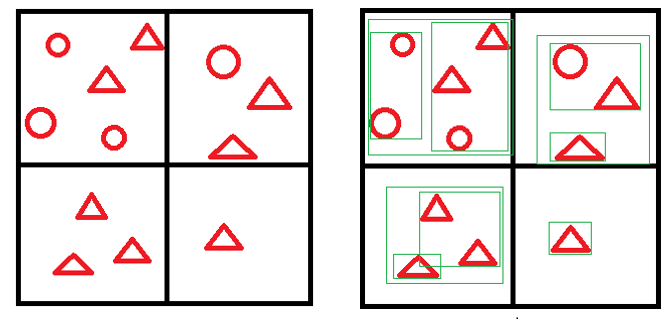
首先,我们可以将整个空间分成许多小网格,并将每个对象(几何体)归类到这些小网格中。 我们为每个小格子分别构建BVH,称之为子树。 在这个算法中,我们将空间分成2^12 = 4096个小格子,并并行构建4096个子树。 之后,我们以SAH为标准,将这些子树组合在一起形成一棵 BVH 树。
因为链表树在内存中效率低。 所以再之后,我们需要将链表 BVH 树“扁平化”为向量数据结构。 根据我的经验,当使用线性树结构时,碰撞检测的总 CPU 时间比链表树结构少 20% 到 30%。 然后,删除链表树以释放内存。
关于该算法的具体实现流程,该链接中给出了详细的步骤,您也可以查看BVH.cpp文件中的源代码。