20 新闻文本分类
这是南加州大学 EE 660 的期末项目。
点击此处获取详细信息。
摘要
在这个问题中,我将使用 20 个具有监督学习和迁移学习的新闻文本数据集,我会先用词嵌入的方法对数据进行预处理。在监督学习部分,我会尝试不同的分类模型对数据进行分类并进行比较。选择最好的模型并在测试集上进行测试。在迁移学习部分,我将再次分离数据以适应迁移学习问题。然后尝试将 Subspace Alignment、Tr Ada Boost 和 Importance Weighting 与监督学习模型结合起来。最后,我将分析结果并做出结论。
这是一个分类问题。该数据集结合了 20 类新闻,包括计算机主题、娱乐主题、科学主题等。我的目标是对 20 个新闻数据集进行分类。我的工作包括两部分,机器学习部分和迁移学习部分。
然后在第 2 部分中,我将尝试结合阶段 1 模型的不同迁移学习方法。并非所有方法都适用于此问题,因此我将比较结果并选择最适用的方法。这个迁移学习部分在某些情况下也很有用。例如,我们有很多机器学习新闻和一些深度神经元网络新闻,因为这是这些年的新话题。从机器学习新闻中获得的信息可以帮助我们通过迁移学习策略为深度神经元网络新闻建立更好的模型。
点击此处查看完整报告。
1. 分类问题
1.1 数据集
我使用的数据集是 20news 数据集,它有几个顶级类别,每个顶级类别都有很多二级类别,甚至三级类别。
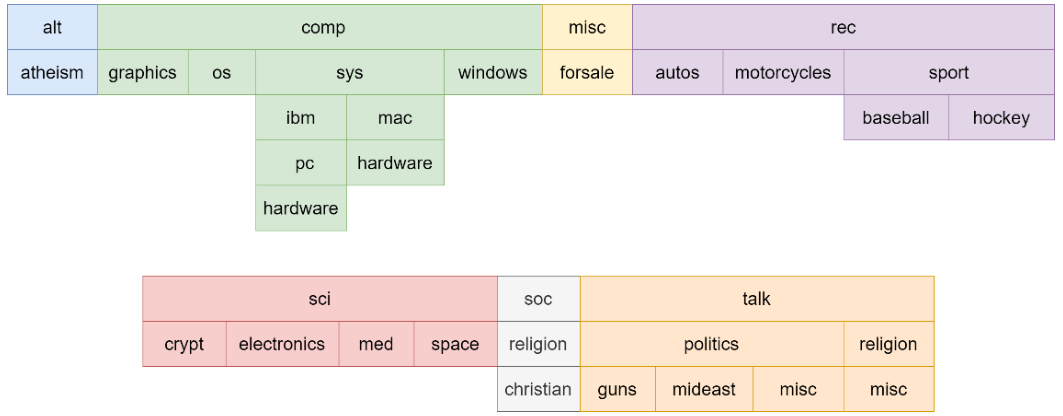
从上图中,有 7 个顶级类别和 20 个子级类别。对于每个类别,它具有如下表所示的数据数量。

共有11269个训练数据,7505个测试数据。数据集的最大方差是 1.61。因此,仅考虑子级别类别时,数据集是平衡的。
1.2 技术路线图
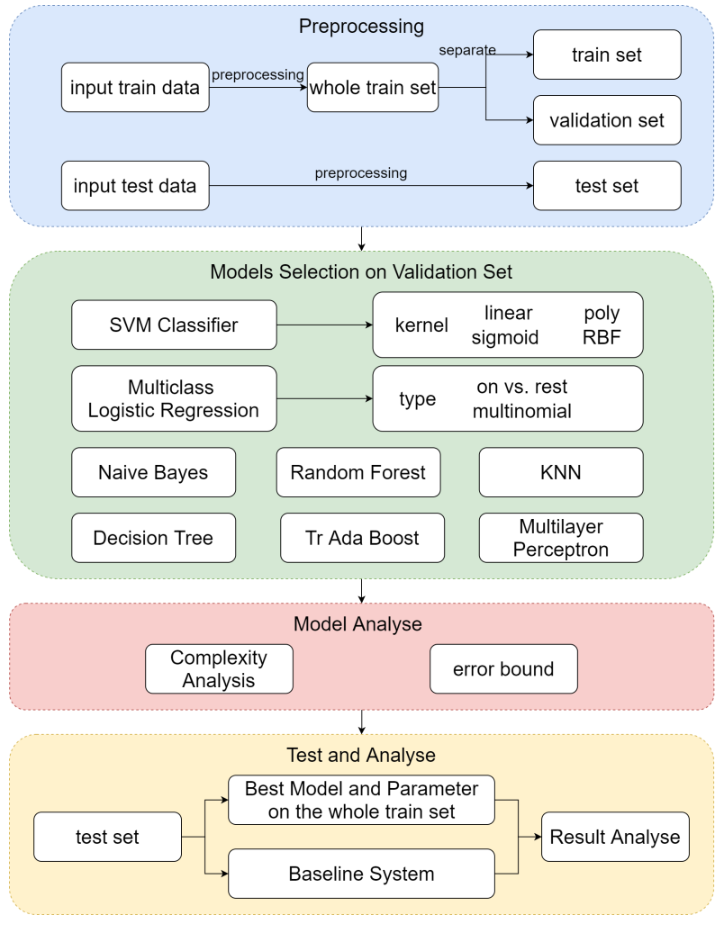
1.3 模型选择与结果比较
训练集的结果(不是整个训练集)。所有精度高于0.99的模型都为粗体表示。

验证集的结果,所有精度高于0.8的模型都是粗体表示。

我在验证集上挑选了所有精度大于 0.8 的模型,并计算了每个类的精度,这就是我得到的。从下图中,我们可以发现所有模型都不擅长分类comp.os.ms-windows.misc、comp.sys.ibm.pc.hardware、comp.windows.x和sci.electronics。

最终结果与分析
我将只使用两个基线模型(普通模型和具有线性核的 SVM)与最佳模型进行比较,该模型是在隐藏层中具有 100 个节点的多层感知器。使用adam进行梯度下降策略,学习率=0.0001,batch size=200,epoch=100,使用ReLU作为激活函数。这次我在整个训练集上训练这3个模型,在测试集上进行测试。
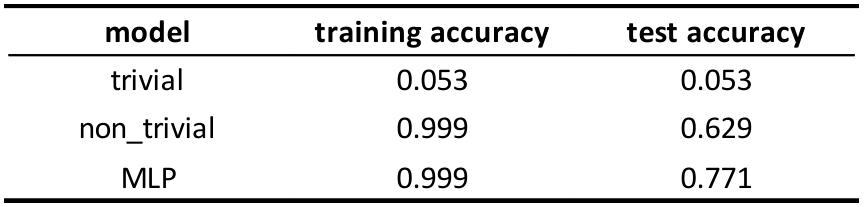
从结果中,我们可以发现 MLP 和 not trivial 模型的准确性都从验证集中下降,我猜可能是训练集与测试集略有不同。样本外误差界限是:
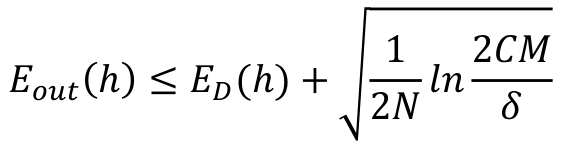
在这种情况下,C = 20,我们假设 δ = 0.1。
在验证步骤中,N = 9016,M = 24。因此,误差界限为 0.023
在测试步骤中,N = 11269,M = 1。因此,界限为 0.016
2. 迁移学习
2.1 数据集
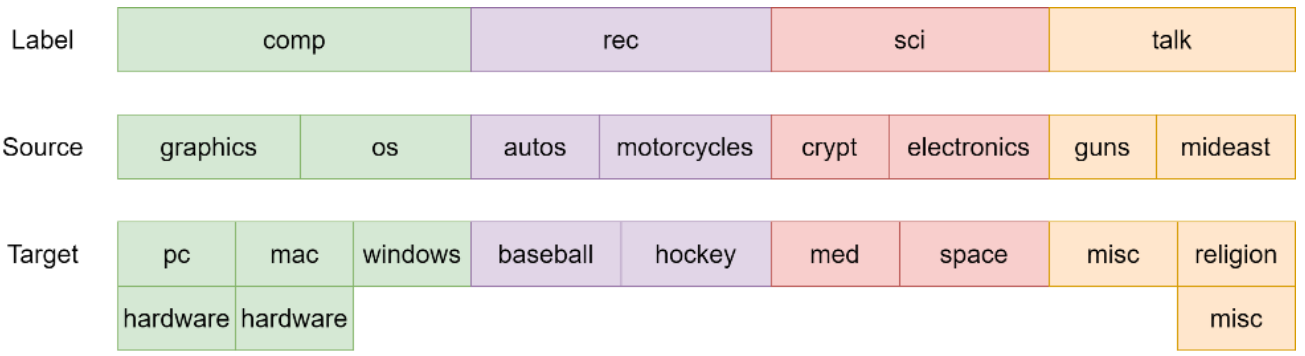
我将使用“comp”、“rec”、“sci”、“talk”作为4个顶层标签,并将相应的数据点标记为0、1、2和3。对于每个顶层组,我将选择前两个子组作为源域数据,其余作为目标域数据。
2.2 技术路线图
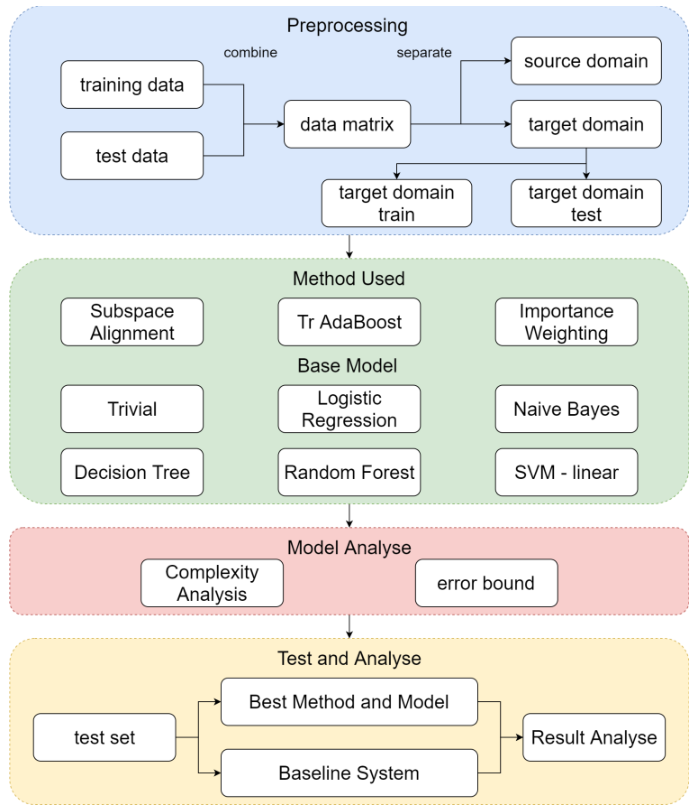
2.3 模型选择与结果比较
SA方法不能使用Naïve Bayes,因为Naïve Bayes要求所有的输入数据都是正的,但是在做变换的时候,有些数据会变成负的。因此,SA 中没有朴素贝叶斯结果

从结果来看,我的结论是:
不同组的分类精度因型号而异。当使用带有 SVM 线性核的基线迁移学习(不使用迁移学习)时,精度最高的是“talk”组。然而,在朴素贝叶斯中,精度最高的组是“computer”。因此,我们不能说哪个组的源域和目标域彼此更接近。
SA方法总是比基线差。因为SA擅长处理低维数据,它需要一些带标签的目标域数据来帮助它“翻转”预测。在这个问题中,数据是高维的,不适合用这种方法。调整源域中的数据分布会使模型预测出错误的结果。
从上表来看,Tr Ada Boost 总是优于baseline。因为 Tr Ada Boost 是这里唯一使用目标域数据和标签来帮助它调整权重值的模型。它是面向目标的,始终使用目标数据和标签来使模型在目标域上表现更好。
只考虑使用 Tr Ada Boost 和朴素贝叶斯的最佳性能模型的误差范围。
样本误差界限是:
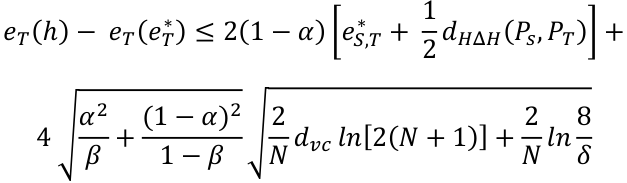
其中 α: 错误在目标域中的重要性,假设它是 0.5
β: 从目标域中提取的标记数据点的分数,在本例中为 7735/ (7735+4140) = 0.651
eS,T* : 组合误差 = minh∈H {eS(h) + eT(h)}。我重新训练并再次对源域和目标域进行预测,得到 0.255。
dHΔH(PS, PT): 对称差假设散度=2,假设本例为0.1。
在这种情况下,N = 16015,dvc = 2(总共 4 个类),假设 δ = 0.1。
最终的误差接线是:0.54。
3. 总结
文本数据与我之前处理过的所有其他数据完全不同。它是稀疏和高维的,需要一些新的策略来处理。在我使用的所有模型中,无论是监督学习部分还是迁移学习部分,具有线性核的 SVM、朴素贝叶斯、随机森林和逻辑回归始终是处理文本数据的不错选择。
在这个项目中,我只使用one-hot encoding方法对文本数据进行预处理,以后可能会在NLP中尝试其他词嵌入方法,看看它是否表现更好。